
GenAI wciąż przegrywa z Minecraftem
Publicyści zastanawiają się, w jaki sposób sztuczna inteligencja zautomatyzuje pracę. Tymczasem my, badacze, wracamy do kwestii znacznie bardziej fundamentalnej: czy potrafi ona grać w gry?
Nie jest to wbrew pozorom pytanie postawione wyłącznie dla zaspokojenia pustej ciekawości. Zanim powierzymy generatywnym modelom role robotycznych asystentów musimy się przecież dowiedzieć, na ile radzą sobie one z wyzwaniami obecnymi w świecie fizycznym. Niestety, osadzenie AI w mechanicznym ciele i puszczenie jej samopas jest kosztowne, mozolne, a niekiedy: także niebezpieczne. Wirtualne światy okazują się zaś wyjątkowo bezpiecznym środowiskiem do nauki.
Od Ponga do Starcrafta II
Technologiczni giganci, którzy dzisiaj prześcigają się w prezentowaniu chatbotów zdolnych coraz sprawniej odpowiadać na nasze pytania i spełniać zachcianki, dekadę temu poświęcali ogromne zasoby, by uczyć AI grania w gry. Jednym z pierwszych głośnych sukcesów Google DeepMind, dzisiejszych ojców i matek Gemini, było ujarzmienie klasyków rodem ze stareńkiego Atari 2600. W 2013 r. spółka przedstawiła DQN, algorytm potrafiący samodzielnie odkryć strategie nabijające solidne wyniki w Breakoucie, Pongu czy Space Invaders. Gorzej radził on sobie z produkcjami wymagającymi długoterminowego planowania.
DeepMind szybko znalazł sposób również na to. Jego AlphaGo pokonało w 2016 r. Lee Sedola, jednego z najbardziej utytułowanych mistrzów Go. Rok później AlphaZero, znając jedynie podstawowe reguły szachów, w cztery godziny osiągnęło poziom pozwalający prześcignąć Stockfisha, uważanego wówczas za najlepszy silnik szachowy na świecie. Następnie AlphaStar rozgromiło pięć do zera Grzegorza „MaNę” Komincza z Team Liquid, niekwestionowaną gwiazdę sceny Starcrafta 2. Każdy z powyższych algorytmów wyciągał wnioski na podstawie bardzo wątłego sygnału uczącego, po każdej rozgrywce zadając sobie pytania w rodzaju: „Czy mój wynik się poprawił?”, „Czy wygrałem, czy przegrałem?”.
Wraz z debiutem pierwszej iteracji ChataGPT stało się jednak jasne, że od opracowywania sprytnych algorytmów znacznie ważniejsza jest skala: ilość dostępnych danych, wielkość centrum obliczeniowego, poziom komplikacji modelu oraz suma pieniędzy, które jesteśmy w stanie włożyć w jego trening. Zamiast samodzielnie wynajdować nowe strategie, LLM-y (ang. large language models) starają się wszak wiernie kopiować to, co znajduje się w naszym zbiorze danych. A ponieważ zbiorem tym jest cały internet, wyniki ich dociekań zdają się naśladować – mniej lub bardziej udolnie – sposób myślenia ludzi.
Chociaż ani nie zaskoczą one unikalnym gambitem szachowym, ani nie poradzą sobie z (nawet amatorskim) graczem Doty 2, modele językowe mają obszerną wiedzę na wiele różnych tematów. Mimo że nadal dostrzegamy luki w ich odpowiedziach i narzekamy na kuriozalne błędy w rozumowaniu, w związku ze swoim potencjałem komercyjnym LLM-y odciągnęły uwagę naukowców od śrubowania rekordów w grach wideo… No, przynajmniej do czasu.
ChatGPT < roguelike z 1987 r.
Dotychczas jakość wielkich modeli językowych mierzyliśmy, testując ich znajomość wiedzy ogólnej, prawidłowość wnioskowania oraz zdolność rozwiązywania problemów matematycznych. Tyle że w tych obszarach nie doświadczamy już rewolucyjnych skoków, ale raczej powolnego marszu naprzód, podczas którego kolejne kroki będą stawiane z coraz większym wysiłkiem.
Pojawia się pytanie: jakie środowiska testowe powinniśmy postawić przed algorytmami, aby przyspieszyć tempo ich rozwoju? Chociaż potencjalnych kandydatów jest wielu, tak się składa, że gry wymagają właśnie tych kompetencji, z którymi współczesne modele mają największy problem: długoterminowego planowania, myślenia przestrzennego czy adaptacji do nowych sytuacji.
Dla przykładu zaskakująco trudnym orzechem do zgryzienia jest dla LLM-ów NetHack, a więc tekstowy roguelike z 1987 roku. Zgodnie z kanonem gatunku, kluczową częścią gry jest proceduralna generacja: mapa podziemi, które przemierza gracz, po każdej porażce jest tworzona na nowo, a potwory oraz przedmioty są na niej losowo rozsiewane. Z tego względu nie można w banalny sposób wykorzystywać wiedzy z poprzednich podejść, jako że np. zwój ulepszania ekwipunku z jednej partii w kolejnej okaże się zwojem amnezji. Złożoność NetHacka sprawia, że nawet gracze korzystający ze szczegółowych poradników potrzebują dziesiątek godzin aby zakończyć przygodę z sukcesem (a śmiałkom skłonnym przejść ją w ciemno zajmuje to nawet kilkanaście lat!).
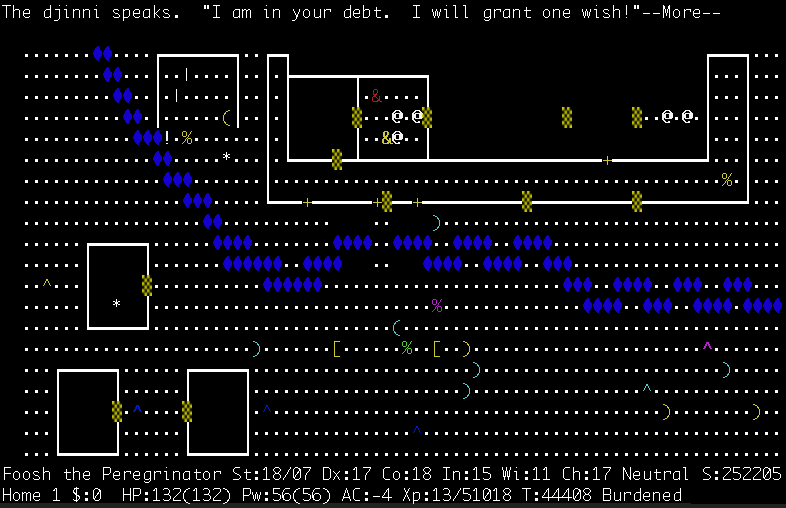
W 2020 roku badacze z Facebooka stworzyli na bazie klasyka środowisko testowe dla sztucznej inteligencji. Przez ostatnie cztery lata niewiele w nim ona osiągnęła, w NetHacku wciąż lepsze okazują się algorytmy bliższe pykającemu w Space Invaders DQN-owi niż współczesnym modelom językowym. Te pierwsze wyciągają w grze ok. 11 tys. punktów, te drugie – poniżej czterystu. Gracze z krwi i kości są tymczasem w stanie wykręcić wyniki idące w setki milionów.
Przepaść bierze się z kiepskiej zdolności LLM-ów do nauki na własnych błędach oraz trudności w łączeniu przez nie swojej bogatej wiedzy z założeniami rozgrywki. Mimo że GPT potrafi wyrecytować podstawowe fakty o NetHacku a także powtórzyć za internetem strategie maksymalizujące szanse na wygraną, postawiony przed klawiaturą będzie miał problem z wykorzystaniem swoich dobrych rad w praktyce. Kluczowe okazuje się tzw. ugruntowanie modelu (grounding), a więc przekładanie przyswojonych wcześniej informacji na kontekst konkretnej rozgrywki.
Świat Nethacka składa się z liter, cyfr i znaków przestankowych, przykładowo postać gracza to @, wchodząc na ^ następujemy w istocie na pułapkę, zaś pod % kryje się jedzenie. Sztuczna inteligencja wie z poradników, że D symbolizuje w nim smoka, ale w trakcie rozgrywki nie jest w stanie połączyć tej informacji z tym, co widzi (nic w tym zresztą dziwnego, sami możecie przeczytać w książce, jak wygląda modrzew, a idąc przez las i tak go nie poznać). W związku z tym nie ma pojęcia, czy na widok D powinna atakować, uciekać, a może użyć mikstury leczącej (i jak ewentualna decyzja o jej użyciu wpłynie na późniejsze szanse zwycięstwa).
Nawet obyty z roguelike’ami człowiek, który przed uruchomieniem NetHacka przyswoi kilka poradników, nie zajdzie podczas pierwszej sesji zbyt daleko. Gracz potrzebuje bowiem popełnić na przestrzeni kolejnych podejść masę pomyłek, doświadczyć ich konsekwencji i – przede wszystkim – wyciągnąć wnioski, z czym LLM-y (jeszcze!) sobie nie radzą.
AI zatrudnia podwykonawcę
W NetHacku nawet jeden nieostrożny ruch (np. przypadkowe zjedzenie zgniłego posiłku) może doprowadzić do rychłego zakończenia zabawy. Prostszym środowiskiem testowym jest Minecraft, którego proceduralnie generowane światy zapewniają unikalny i (teoretycznie) nieskończony wirtualny plac zabaw. Badacze Nvidii pokazali niedawno, że modele językowe są w stanie zajść w grze bardzo daleko, jeśli tylko pozwolimy im na… zbudowanie swojego własnego bota.
Zaproponowany przez nich Voyager wykorzystuje GPT-4 w roli klepacza kodu dla bota, który w trakcie treningu połknął – wraz z całą resztą internetu – informacje o tym, jak walczyć z Creeperami, jak polować na świniaki, a jak używać stołu rzemieślniczego. Model na początku tworzy skrypty do wykonywania prostych zadań: „pójdź tam”, „zetnij drzewo”, „wykorzystaj materiały do craftowania”, a z czasem łączy je w bardziej zaawansowane strategie, pozwalające np. otrzymać drewniany miecz.
Rozwiązanie okazało się strzałem w dziesiątkę z kilku powodów. Po pierwsze, ze względów ekonomicznych. Zamiast analizować każdą klatkę gry i dumać, który klawisz powinien wcisnąć, LLM generuje wszak bota. A ten nie potrzebuje przecież kilkudziesięciu kart graficznych, by podjąć decyzję, w który blok uderzyć kilofem. Po drugie, rozumowanie na bazie zmiennych i funkcji jest dla modeli językowych zdecydowanie bardziej naturalne – myślenie przestrzenne to dla LLM-ów nadal problem, tymczasem z klepaniem kodu są one za pan brat.
Po trzecie, o sile Voyagera stanowi jego zdolność wyciągania wniosków z własnych pomyłek. Każdy wygenerowany przez GPT-4 skrypt jest odpalany w Minecrafcie i testowany. Po zakończeniu sesji model językowy otrzymuje zaś informację zwrotną: gdzie kod się wykrzaczył, co poszło źle, z jakiego powodu gracz umarł. Na bazie udzielonych odpowiedzi Voyager tworzy kolejną wersję, poprawiając felerne fragmenty, co z czasem pozwala mu dążyć ku coraz bardziej skomplikowanym celom.
Po 125 iteracjach jest on w stanie wytworzyć diamentowe narzędzia, co wymaga długoterminowego planowania: budowy kuźni, odnalezienia złóż diamentów i pozyskania ich przy użyciu żelaznego kilofa. By jednak w ogóle chwycić za żelazny kilof, potrzebujemy zdobyć drewno i żelazo oraz postawić piec, co rodzi kolejne trudności. Rozpracowywanie minecraftowego drzewka technologii to ciekawy przykład tzw. uczenia się w kontekście, a zarazem spora różnica względem „klasycznego” trenowania LLM-ów.
Słowem wyjaśnienia: gdy ChatGPT ma dokończyć zdanie „kot pije…”, przewiduje on kolejne słowo na podstawie parametrów – podpowiadają one, że kot może pić mleko (50% szans), wodę (30%) lub herbatę (20%). Zazwyczaj trening LLM-ów polega na karmieniu algorytmu masą stron internetowych, książek czy artykułów, modyfikując w ten sposób parametry, co zwiększa szansę na udzielenie prawidłowej odpowiedzi. Zamiast jednak zmieniać parametry, Voyager nabywa nowe umiejętności poprzez rozumowanie za pomocą języka, w tym przypadku: kodu. Gdy natrafi on w Minecrafcie na przeszkodę (np. rzekę), pisze nowy skrypt (zbuduj: most) i testuje go. Jeśli podczas kolejnej sesji okaże się on niewystarczający (bo most ulegnie zniszczeniu) – wprowadza w życie niezbędne korekty.
GPT-5 Gamer
Badacze z Pekinu nie ograniczają się do eksplorowania pojedynczej gry. Zamiast tego Chińczycy tworzą środowisko testowe, które pozwoli nam zamienić GPT w gracza uniwersalnego. W ramach projektu Cradle ich model językowy wciela się w użytkownika siedzącego przed komputerem. Na podstawie klatki z gry lub aplikacji musi on wybrać, gdzie przemieścić kursor i jaką kombinację klawiszy wcisnąć.
Okazuje się, że współczesne LLM-y są na tyle sprytne, by zaliczyć pierwsze misje w Red Dead Redemption 2, stworzyć całkiem skomplikowane miasto w Cities: Skyline, zasadzić pasternak w Stardew Valley czy wysyłać maila z poziomu przeglądarki. Choć technologia dopiero raczkuje (operuje w raptem dwóch klatkach na sekundę i nie zawsze potrafi zrozumieć, co właściwie dzieje się na ekranie), tkwi w niej ogromny potencjał na przyszłość. Taki wirtualny asystent mógłby przecież podjąć się opracowania szczegółowych raportów, zmontowania filmów, a nawet przeprowadzania symulacji i analiz naukowych – nie wymagając z naszej strony nawet jednego kliknięcia myszą.
O stworzeniu uniwersalnego gracza marzy też Google DeepMind, choć zamiast testować dostępne na rynku modele, spółka woli go sobie sama wyszkolić. Opierając się na obserwacji, że chatbotowa rewolucja była możliwa dzięki operowaniu na gigantycznych ilościach danych, jej inżynierowie tworzą własny, zupełnie unikalny zbiór treningowy, który ma pozwolić na skuteczne funkcjonowanie w każdym z wirtualnych światów.
W ramach projektu SIMA DeepMind nawiązał współpracę z autorami m.in. No Man’s Sky’a, Goat Simulatora 3, Valheima czy Space Engineers oraz zatrudnił ludzi, którzy wykonywali w tych grach proste czynności („wejdź do statku”, „zbierz maliny”, „zetnij drzewo”). Powstał w ten sposób zbiór składający się z duetów: polecenie w formie tekstowej & sekwencja akcji, które człowiek podjął do jego realizacji.
SIMA ma być receptą na wspomniany przy okazji NetHacka problem ugruntowania. Przystępując do gry, klasyczne modele językowe są dziś w stanie wyczytać w sieci, że powinny zająć się „eksploracją” podziemi – nie zawsze umieją jednak powiązać to pojęcie z konkretnymi działaniami w środowisku gry. Nie rozumieją bowiem, że „eksploracja” oznacza w nim nie tylko „poruszanie się”, ale również „poszukiwanie przedmiotów”, „unikanie pułapek”, „zarządzanie zasobami” albo „pokonywanie potworów”. SIMA z kolei, przypomnijmy, opiera się na zbiorze działań podejmowanych w określonych sytuacjach przez człowieka. Potrafi zatem powiązać tekstowe polecenie „eksploracji” z czynnościami, jakie podejmują w tym celu żywi gracze.
Wpływ księżyca
W ramach pracy naukowej zajmuję się m.in. algorytmami uczącymi się, jak grać. W naszym zespole badawczym testowaliśmy ostatnio różne podejścia do nauki NetHacka: przez kilka tygodni sprawdzaliśmy, które z modyfikacji kodu poprawiają, a które pogarszają wyniki modelu.
Któregoś dnia jego efektywność gwałtownie spadła – z oczekiwanych pięciu tysięcy punktów spadła do poziom raptem trzech tysięcy. Rozczarowani, cofnęliśmy wprowadzone właśnie zmiany, odpaliliśmy trening jeszcze raz i… znowu zdobył on trzy tysiące! Podejrzewając, że w kodzie pojawił się błąd, przeczesaliśmy nasze wcześniejsze modyfikacje – bez skutku. Zmieniliśmy nawet maszynę obliczeniową, obawiając się że może padliśmy ofiarą awarii sprzętu, ale i to nic nie dało.
Finalnie problemem okazały się… faza księżyca. Korzystając z zegara systemu operacyjnego, NetHack potrafi bowiem wnioskować, kiedy użytkownik może zaobserwować za oknem pełnię. Mechanika nieco się wówczas zmienia, przykładowo gracz częściej trafia w podziemiach na wilkołaki. Zgadnijcie, w jakiej fazie satelita Ziemi był tego felernego dnia, gdy wyniki algorytmu się pogorszyły?
Pech chciał, że w naszym zbiorze treningowym nie było danych zebranych w trakcie pełni, przez co agent AI nie potrafił uporać się z nadobecnością likantropów. Anegdota stała się viralem na X (dawnym Twitterze), zyskując ponad 2 miliony wyświetleń, zaowocowała także artykułem na ArsTechnice oraz na japońskim blogu technologicznym GIGAZINE. Spróbuję przełknąć słodko-gorzki fakt, że najbardziej poczytnym artefaktem moich badań będzie ten zabawny wpis.
Dwa bratanki
Sporo słyszymy o zastosowaniu sztucznej inteligencji w branży, acz głównie w kontekście zautomatyzowania produkcji: algorytmy mają stworzyć za nas prototypowe assety, wspomóc pracę scenarzystów albo ułatwić programistom klepanie kodu. Tymczasem gamedev i modele generatywne weszły w okres symbiozy: gry wideo stają się lepsze dzięki AI, zaś AI uczy się dzięki grom wideo. Musimy się ich związkom przyglądać, nawet jeśli jeszcze nieraz będziemy przez nie wyć do księżyca.